会议观察 | 2023世界人工智能大会WAIC精彩回顾 原创

2023年7月6日-8日,2023世界人工智能大会WAIC在上海召开,至顶智库对本次大会高度关注,研究团队前往会议和展览现场观摩学习,并与相关企业专家进行深度访谈交流,本文为大家分享大会的精彩瞬间,详情见下文。
中金投融资主题论坛
高端对话
中金公司原总裁兼首席执行官 、清华大学管理实践访问教授 朱云来
清华大学教授、智能产业研究院(AIR)院长、中国工程院院士 张亚勤

图片来源:2023世界人工智能大会—投融资主题论坛
- 大模型能力很强,但是也有其局限性,分别是时效性、准确性和效率。目前不完全清楚局限是什么,甚至有可能是算法本身无法解决的问题。另外,降低耗能,增加效率也是很重要的问题。大模型本身固然重要,但是在垂直行业的应用对于精准性要求更高。
- 人工智能带来的很大变化是很多领域不再需要工作者。在一个综合的维度上,大模型大大超出了人们的想象力。但是从局限性来讲,我们需要一个新的阶段后,才会接近通用大模型的能力。人工智能把人替代后,会对社会产生重要影响。对于资本、技术来说,这将由谁来决定是一个重要的问题。科技迅速发展,改变的是我们社会的治理结构。大模型带来的成果,应该由社会共享。
- 在大模型相关领域,不只是国家能成为核心玩家或唯一玩家,小公司在AI市场上也会发挥巨大的作用。我们需要有大模型平台,同时,大模型平台的存在也会使AI领域相关研究的门槛变低。平台是实现科技进步的很好优势,但是不能被超越的平台本身也会产生惰性。如果没有进步的冲动,社会技术发展将趋于稳定,从这个角度而言,相关领域小公司的发展非常必要。
“聚焦·大模型时代AIGC新浪潮”论坛
超越单一模型:大规模语言模型在下一代知识工具中的应用——印象笔记董事长、首席执行官 唐毅
图片来源:2023世界人工智能大会—“聚焦·大模型时代AIGC新浪潮”论坛
印象笔记很快将会公布基于知识加持的2.0产品,其可以全面地对所有的知识和工作的场景进行赋能,进行开放式的对话。特别重要的是,其可以基于关键语料总结的专有大模型的知识能力,结合每一个人、每一个企业、每一个团队多年所积累的知识,在多模态的场景下进行知识处理、知识回忆、知识获取、知识搜索、知识连接,以及自动生成一系列的多模态工具和内容。
通用模型有很多优势。大模型的巨大优势是由通用模型大量的通用知识的训练、非常众多的参数以及非常强的算力和算法构成,所以才具有不断的推演。但是通用模型也存在几个问题:
第一,由于大模型是世界知识训练,是通才而不是专才,那么一定要有专有数据才能训练出专有知识;第二,虽然成本在不断下降,但是成本依然很高;第三,数据安全一定不会符合很多企业的要求;第四,大模型存在的幻觉问题需要通过可解释模型来确保内容真实可信。
在以上前提下,印象笔记做了多次迭代大象GPT的千量级支持大模型。通过一系列的像模型压缩、模型量化等在软件工程方面的部署,提供给用户非常高性能的、已经上线全面可用的支持大模型驱动的印象AI产品、场景和解决方案。大象GPT将向着模型高性能、模型小型化、模型插件增强以及持续的语料数据集的增强来给用户提供更强的多模态产品和技术服务。
AIGC发展挑战与趋势透析
清华大学国强教授、智能产业研究院(AIR)首席研究员 聂再清
上海人工智能实验室教授、主任助理 乔宇
商汤“商量SenceChat”大语言模型技术总负责人、香港中文大学助理教授 王历伟
蚂蚁集团机器智能部副总经理、蚂蚁安全天算实验室主任 张天翼
云天励飞副总裁、AI技术平台总经理 肖嵘

图片来源:2023世界人工智能大会—“聚焦·大模型时代AIGC新浪潮”论坛
- 大模型的核心观念在于通用能力强,可以应对多个问题。人之所以能够具有很多专用的能力,关键在于人的基础,大脑模型和常识是专用能力的基础。对于通用大模型,大是手段,通用是目的。关于通用模型的发展趋势,就像飞机从发明初只是探险者的游戏到今天非常发达的航空工业。大模型目前面临着很多挑战,但是要用发展的眼光来看,相信人类的智慧。
- 对于大模型研发的门槛,重要的是人才的培养。从研究进展、人才培养的速度来看,未来大模型研发的门槛会降低。目前关于算力的需求依然旺盛,而且训练单次大模型的算力成本看起来也会更乐观。
- 有关于大模型未来的发展,主要将体现在以下四个方面。第一是幻觉问题,即解决事实确认和一些引用的问题。目前已经有了一些简单的解决方案,但是没有本质解决。第二是工具使用和外部知识整合的能力,只有解决了这些方向,才能解决行业应用落地的问题。第三是比较难的问题,有关于研究与推理,我们需要展现大模型的逻辑能力。第四是持续学习能力,由鉴别式向生成式迈进,但是目前的生成式精度依然让人不满意。
- 关于大模型的透明性、稳健性、对人类的忠诚,需要实现模型决策本身的可解释性。从学校研究角度阐述,关于如何理解和评价大模型的能力,包括安全性、AI治理等内容,正在引起学术圈的创新与探索。目前看来,大模型幻觉及其产生的风险应被重新定义。对于安全问题要从发展的角度来看。新形成的能力存在着安全问题,如可信性,鲁棒性,价值观,隐私保护等问题。面对可能存在的问题,不能一刀切,应当细化分析。同时,我们应当从大模型的不同环节思考安全问题,并且展开更多的国际交流合作。
容联云 「生成式营销服务与大模型」 论坛
容联云正式发布面向企业应用的垂直行业多层次大语言模型“赤兔大模型”,并发布容联云“生成式智能营销服一体化工作空间——机器猫”和“生成式一体化智能客服平台”,旨在推动企业营销和服务数智化转型。
容联云发布大语言模型“赤兔”

图片来源:2023年世界人工智能大会—容联云 「生成式营销服务与大模型」 论坛
赤兔大模型是容联云面向企业应用的垂直行业多层次大语言模型,通过重构智能客服和数智化营销价值,赋能沟通智能2.0时代。基于“赤兔大模型”,企业可以搭建自己的智能客服和数智化营销,完成从“降本增效”到“价值创造”的进化。沟通智能已经进入2.0时代,在赤兔大模型加持下,智能沟通2.0将在AI基础能力、会话分析洞察、对话能力、人机协同四个方面有大幅提升。
赤兔大模型聚焦懂交流、会分析、有知识、能执行“四大能力”,为智能客服和营销等场景保驾护航。依托赤兔大模型,企业客服可以实现多维度、细粒度的对话分析理解与内容生产,通过意见挖掘、情感分析、立场检测等洞察用户需求,同时,赤兔大模型还针对多种场景的人机交互应用,自动生成业务话术及流程方案、问答知识库,提升AI运营效率、客服效能及销售转化。其次,丰富的内部知识储备,和灵活的外部知识运用,可以解决大模型在真实性、即时性、逻辑性、可控性等方面的问题。在行业服务中,赤兔大模型会更加务实地提供大模型的落地应用技术方案。针对于不同领域、场景服务,“赤兔大模型”可以实现单点能力的升级、单点能力的新增,以及流程逻辑的革新。
容联云发布生成式智能营销服一体化工作空间——机器猫

图片来源:2023年世界人工智能大会—容联云 「生成式营销服务与大模型」 论坛
容联云COO熊谢刚发布生成式智能营销服一体化工作空间“机器猫”,为企业用户提供丰富的生成式智能场景应用,一“处”即发,助力企业服务数智化。据介绍,容联云“机器猫”平台提供的生成式智能应用,首批落地四大应用场景,包括客户联络、业务协作、AI辅助、智能洞察。在客户联络方面,区别于传统纯人工方式和NLP机器人解决部分服务场景,大模型机器人可解决大部分服务场景,同时进一步降低机器人维护成本和客服数量,用户体验提升60%;在业务协作方面,通过赤兔大模型提供更加智能高效的灵活集成、生成式策略推荐、智能填单、智能分配、智能标签提取等能力,进一步降低AI运营成本,降低客服服务时长和客诉数量,提升坐席效率;在AI辅助方面,生成式智能应用赋能下的AI辅助,不再是CC的附加工具,而真正高效帮助企业解决管理难题,实现销售业绩提升;在智能洞察方面,基于诸葛智能,“机器猫”平台可为用户提供各种分析模型、行业指标体系问询,也可以提供实践、经验分析,帮助企业快速成长为分析专家,对于数据报表与指标、用户标签与画像等分析结果,用户可以通过语音、文字等多种方式进行问答,并得到快速反馈,还可通过语音等驱动进行报表定制。
中国智能客服市场繁荣 容联云发布生成式一体化智能客服平台
容联云针对客户联络服务场景推出“生成式一体化智能客服平台”,全面赋能客服&营销场景应用。容联云数字智能云事业群运营总经理王春生介绍,当前智能客服从AI1.0时代进入AI2.0时代,基于赤兔大模型,容联云生成式一体化智能客服平台可以将知识生产效率提升70%,对话构建成本下降80%,100%提升客户服务效率,并为客服人员提供文档智能问答/抽取、用户语料/业务话术/流程类方案建议自动生成、销售优秀话术自动提炼等能力,助力客服员工高效推进业务服务。
百度发布“文心大模型3.5”

图片来源:2023年世界人工智能大会,百度官方公众号
百度发布“文心大模型3.5”,其在效果、功能、性能全面提升,实现了基础模型升级、精调技术创新、知识点增强、逻辑推理增强等,模型效果提升50%,训练速度提升2倍,推理速度提升30倍。
在基础模型训练上,采用飞桨最先进的自适应混合并行训练技术及混合精度计算策略,并采用多种策略优化数据源及数据分布,加快了模型迭代速度,显著提升了模型效果和安全性。
创新多类型多阶段有监督精调、多层次多粒度奖励模型、多损失函数混合优化策略、双飞轮结合的模型优化等技术,进一步提升模型效果及场景适配能力。
在知识增强和检索增强基础上,文心大模型3.5提出“知识点增强技术”,对用户输入的查询、问题等进行分析理解,解析出生成答案所需要的相关知识点,之后运用知识图谱和搜索引擎为这些知识点找到相应答案,最后再用这些知识点构造输入给大模型的提示,为大模型注入更具体、更详细、更专业的知识点,显著提升大模型对世界知识的掌握和运用。
在推理方面,通过大规模逻辑数据构建、逻辑知识建模、多粒度语义知识组合以及符号神经网络技术,提升文心大模型3.5在逻辑推理、数学计算及代码生成等任务上的表现。
新增插件机制,文心一言已于6月17日对外发布官方插件百度搜索和ChatFile。百度搜索是默认的内置插件,使得文心一言具备生成实时准确信息的能力。ChatFile是长文本摘要和问答插件,支持超长文本输入。
商汤科技展区:日日新大模型

图片来源:2023世界人工智能大会—商汤科技展区
SenseChat商量-商汤自研中文语言大模型
“商量SenseChat”是商汤科技“日日新SenseNova”大模型体系下的千亿级参数语言大模型,拥有领先的语义理解、多轮对话、知识掌握、逻辑推理的综合能力。最新升级的“商量SenseChat 2.0”在知识信息准确性、逻辑判断能力、上下文理解能力、创作性等方面均有大幅提升。
SenseMirage 秒画-AI内容创作社区平台
商汤“秒画SenseMirage”是一个包含商汤自研AIGC大模型和便捷的LoRA训练能力,并提供第三方社区开源模型加速推理的创作平台,为创作者提供更加便利、完善的内容生产创作工具。“秒画SenseMirage”可以结合输入的图片或文本智能创作出与输入相关的图像内容,具有更强大的中文理解能力、更多样化的风格选择,模型内使用了flash attention的算子优化技术,作图速度提升3倍。平台内包含多个商汤自研模型及用户分享的社区模型,同时还支持用户finetune、动作控制等功能。商汤秒画SenseMirage 3.0的自研生成大模型参数提升至70亿量级,带来更强图片生成效果,实现专业摄影级细节刻画,使所生成图片具备超强质感和精细度。
SenseAvatar如影- AI数字人视频生成平台

图片来源:2023世界人工智能大会—商汤科技展区
基于“商汤日日新SenseNova”大模型体系,商汤推出“商汤如影SenseAvatar”AI数字人视频生成平台。该平台基于AI数字人视频生成算法、语言大模型、AI文生图、AIGC等多种能力,能够轻松实现高质量、高效率的数字人视频内容创作。基于强大领先的AI生成能力和便捷易用的使用体验,“如影”平台仅需一段2-5分钟手机拍摄的真人视频素材,就能生成动作、表情、口型,甚至发丝都能如真人一般自然的逼真复刻,且多语种精通的数字分身。通过对海量真人基础数据的有效学习,“如影”平台生成的数字人外貌更真实、动作表情更自然,对输入的素材也更加鲁棒。
商汤如影SenseAvatar 2.0的综合性能全面提升,实现“流式生成”模式,直播效率翻倍;在英语、日语、西班牙、阿拉伯语等多语种的精准度提升30%以上,让数字人的语音和口型匹配度更流畅自然;并实现电影级4K高清视频输出效果,成片质量更精良。不仅如此,如影2.0还为数字人的生成和应用带来全新玩法,在即将发布的版本中,用户可以通过输入提示词(Prompt)自动生成与描述匹配的专属数字人形象,还可实现数字人歌唱功能,便捷打造虚拟艺人和网红,或通过大模型生成短剧脚本,生成数字人短片。
SenseThings 格物-商汤NeRF物体重建及营销服务平台
“格物SenseThings”是商汤科技基于神经辐射场技术(NeRF)的3D内容生成平台,能够将各品类的物体超细节的复刻还原,生成的各类3D内容能够在平台上进行再创作,打通3D内容生成场景中采集、重建、浏览、再创作的全链路,通过高精度、高效率、低门槛的数字资产生产,满足电商平台、家装设计、文物数字化等领域行业需求。“格物”支持多种物品品类的复刻,并突破了行业难题——高反光、镜面物体的复刻,比如珠宝首饰,小家电,金属物件等。
SenseSpace琼宇-商汤NeRF 数字孪生应用平台

图片来源:2023世界人工智能大会—商汤科技展区
SenseSpace琼宇是商汤科技基于神经辐射场技术(NeRF)的3D内容生成平台,具备高精度城市级大尺度的空间重建生成能力,生成的3D内容能够在平台上进行再编辑再创作,通过海量高精度数字资产的生产,满足数字孪生、建筑设计、影视创作等行业需求。琼宇平台已经应用于多个城市级数字孪生场景,以超逼真实景三维空间作为数字孪生底座,融合IoT信息、BIM等多源数据,提供3D测量、模型裁剪编辑以及实时视频流空间融合等数字孪生应用功能,覆盖城市管理、规划和运营等应用场景,在“马山镇CIM平台赋能区域投资开发建设”、“合肥中国视界园区数字孪生应用”、“上海瑞金医院应用案例”等多个项目中应用。
第四范式携「式说」大模型亮相WAIC

图片来源:2023世界人工智能大会,第四范式
2023年7月6日-8日,以“智联世界 生成未来”为主题的2023世界人工智能大会(WAIC)在上海隆重开幕。本届大会以“生成式AI”为切入点,聚焦前沿科技创新和最佳产业实践。作为本次大会的重要参与者,第四范式携旗下多模态大模型「式说」亮相现场,展示其在金融、零售、房地产、航空、制造、司法等行业最具代表性的应用实践。
第四范式将大模型技术聚焦在企业软件领域,提出AIGS(AI-Generated Software)的技术战略:以生成式AI重构企业软件。与生成图片、生成海报、生成文案等大家所认知的AIGC不同,「式说」定位为To B(企业级服务)领域的多模态大模型,拥有输入输出多模态、知识库、Copilot、思维链等核心技术,同时具备内容可信、成本可控、数据安全等“企业级”优势。
「式说」大模型保证企业能私有化部署大模型,所需算力成本相对可控。其次,「式说」在学习行业知识后生成内容更加专业,并且在信息输出时定位原始出处,实现所有信息都“有据可查”。最后,「式说」能做到随着用户的反馈知错能改,为企业应用大模型进行业务创新提供数据安全、内容可信、成本可控的三大保障。
至顶智库分析师与第四范式副总裁涂威威交流

图片来源:2023世界人工智能大会,至顶智库
在WAIC大会期间,第四范式副总裁、主任科学家涂威威接受至顶智库执行主任兼首席分析师孙硕的专访,就生成式AI当前产业发展状况及第四范式提供的解决方案进行相关介绍。
涂威威认为,企业想要落地大模型应用,需要满足3大条件:形成高质量的闭环数据、具备思维链学习能力、解决大模型落地效率问题。这其中,打造数据闭环是关键,结合环境学习让机器从实际决策环境中学习更高层级的目标,是未来打造更强企业智能助手的核心手段。在落地效率方面,企业落地不必执着于单一超级大模型,可以考虑组合多个专业模型各司其职来解决。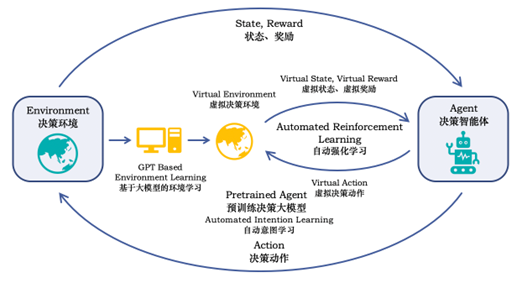
图片来源:第四范式
思维链(Chain-of-Thought)是指参考人类解决问题的方法,从输入问题开始的一系列自然语言形式的推理过程,最终得到输出结论。真实场景中无法让机器进行无限次的试错过程,但大模型可采取构建“虚拟事件模型”的方式在虚拟事件中进行多次迭代,再将最优结果应用到真实事件中。通过利用大模型提供的基础世界常识模型,结合环境学习,让机器从真实的决策环境中学习更高层级的目标,通过离线训练与在线微调结合的方式,在获得高阶推理能力的同时,大幅降低试错成本。
涂威威谈到,第四范式的优势在于长期专注于人工智能的企业级软件开发,公司目前基于南京大学LAMDA实验室提出的“学件”思想构建可重用、可演进和可了解的“企业级大模型学件群组”。
图片来源:第四范式
「学件(learnware)」思想是由南京大学周志华教授在2016年提出,用户通过学件的形式为任务找到合适的机器学习模型。如果模型基于性能优良的学件构建,少量数据也能获得强大的机器学习模型。涂威威表示,企业落地大模型更合理的做法不是把所有的预算都投入到一个超级大模型中,而是可以通过组合多个专业模型各司其职来解决。这就如同人类大脑有不同的分区,不同分区负责不同职责一样。这种方式更利于模型迭代、维护,同时更利于控制成本。“式说大模型学件群”利用各类模型的优势提供更适合客户的综合解决方案。
墨芯公布最新大模型适配成果

图片来源:2023年世界人工智能大会——墨芯人工智能展区
2023年7月6日,在世界人工智能大会WAIC上,AI芯片企业墨芯人工智能发布了最新的大模型适配成果:墨芯AI计算平台在业内率先支持高达千亿参数的大语言模型,并在吞吐、延时等多项指标上表现优异,创下AI芯片行业的又一里程碑。在活动现场,墨芯展示了1760亿大模型Bloom在墨芯AI计算平台上的推理效果,成为全场热点。Bloom是与ChatGPT同等参数量级的开源大语言模型。在墨芯AI计算平台高吞吐、低延时的强大算力支持下,Bloom能够快速完成问答、创作等语言类生成任务。
AI大模型参数暴增,对芯片等算力基础设施带来巨大挑战。墨芯支持高达千亿参数模型,成为业内为数不多的、能够支持大模型落地的AI芯片企业。在ChatGPT等在线式AIGC应用中,AI内容生成速度是最关键的指标之一,墨芯的AI计算平台展示出高吞吐、低延时的优势。在千亿参数大模型上,8张墨芯S30计算卡吞吐达432 token/s,大幅加快响应速度,性能超过主流GPU,使用户能够更快地获得内容,提升用户体验。
在ChatGPT席卷全球后,基于大模型的AIGC应用迅速兴起,数月内仅国内就有三十余家AI企业推出了大模型产品,以AI芯片为核心的大量算力基础设施更是成为焦点。算力是AIGC竞争的"燃料",AI企业必须先解决算力问题,才能在市场中保持竞争力。算力昂贵已经成为困扰众多企业的难题。由于算力供需严重不足与AI企业正面临算力降本增效的迫切需求,业界逐步达成共识:算力的突破口,必须从结合AI模型本身的特性,走软硬协同的道路——稀疏计算。
稀疏计算的原理是:模型运行时仅激活对处理输入有帮助的参数,即无效元素不纳入计算过程,从而大幅减少计算量。这样一来,大模型发展与算力的矛盾能够得到根本解决:技术计算使大模型可以在参数量上跃升若干个数量级的同时,又缓解了算力负担,为大模型的持续发展带来空间。墨芯基于稀疏计算重新设计芯片架构,推出Antoum(R)芯片。

图片来源:2023年世界人工智能大会——墨芯人工智能展区
墨芯Antoum(R)是全球首款高倍率稀疏芯片,支持高达32倍稀疏率,将此前的业界纪录整整提升16倍。此次,基于Antoum(R)芯片的墨芯AI计算卡支持千亿参数大模型,赢得各界关注;在此之前,墨芯也已用多次佳绩证明实力:在众多国际巨头参加的国际权威测试MLPerf 中,墨芯AI计算卡两度问鼎世界冠军,更是在今年的MLPerf中斩获双料冠军。而且这是墨芯Antoum(R)芯片为12nm制程的情况下,取得了比7nm等更先进制程产品更好的成绩,体现出稀疏计算的巨大优势与潜力。
在商业进展上,墨芯也步伐迅速,取得骄人成绩。墨芯AI计算卡产品仅数月就达成销售、实现量产,已在互联网、生命科学领域成单落地;已完成百度飞桨等AI框架、浪潮、新华三等主流服务器的适配,并加入龙蜥等国内操作系统生态。
来源:至顶网至顶智库频道
好文章,需要你的鼓励